
General Game Playing With Schema Networks
Posted August 2017 Back to Resources
Introduction
The success of deep reinforcement learning (deep RL) in playing games has resulted in a large amount of excitement in the AI community and beyond (Mnih et al., 2015; Mnih et al., 2016; Silver et al., 2016; Van Hasselt et al., 2016). State-of-the-art scores in many different games have now surpassed human level. But to what extent do these feats demonstrate that the AI has developed a human-like understanding of the objectives of the game?
When humans play a new game, they first develop a conceptual understanding of the game. Suppose you were seeing a game like Breakout (see below) for the first time. Within a few seconds of observation, you’d start interpreting the game in terms of your prior experience with the world. You would probably interpret the moving red pixel as a ‘ball’ which ‘bounces’ on the ‘side walls,’ and identify a ‘paddle’ that can be moved to bounce the ball. You would understand that the paddle can cause the ball to bounce. You would observe that the ‘bricks’ at the top disappear when the ball hits them. You may not even have looked at the score yet, but now you start noticing that breaking a brick with a ball gives you points, and letting the ball go below the paddle causes you to lose them; you have discovered the game’s objective. Within a few frames of simply observing the game being played, you are very likely to get the concepts of the game.
Understanding the world in terms of cause and effect is one of the hallmarks of human intelligence. This ability allows us to quickly understand new situations, like a new video game, by transferring the conceptual knowledge we have gained elsewhere.
The question, then is: Do deep reinforcement learning agents understand concepts, causes, and effects?
A deep RL agent trained with state-of-the-art Asynchronous Advantage Actor-Critic (A3C) on Vicarious’s standard version of Breakout (see paper for details).
Deep RL wins the game but misses the point
We trained a deep RL agent using state-of-the-art Asynchronous Advantage Actor-Critic (A3C) (Mnih et al., 2016) to play a typical Breakout game, which it learned to play admirably well (above). An intelligent agent that can play a standard game of Breakout should readily adapt to minor variations of the game (Rusu et al., 2016), like a higher paddle or an extra wall. The figures below show the same A3C agent that achieved expert scores on the original game playing several simple variations. If the A3C agent had learned a conceptual understanding of the cause and effect, it should have no trouble adapting to these new aspects of the game.
The deep RL agent is clearly unable to cope with these minor variations because A3C and other deep RL agents work by mapping patterns from the input pixels to an action, like move left or right. The agent regresses from a set of input pixels to a particular action, learned through extensive trial and error. A3C overfits to a narrow strategy that exploits the specific statistics of the version of the game it was trained on, but it has not gained a conceptual understanding of the game’s dynamic or rules. This kind of RL is called model-free because the agent does not develop a predictive causal model of the world. Deep RL behaviors that often get interpreted as ‘intelligence’ are simply stimulus-response mappings that rely on brittle cues.
Schema Networks
At the upcoming 2017 International Conference on Machine Learning (ICML), we will introduce the Schema Network, a model-based approach to RL that exhibits some of the strong generalization abilities we believe to be key to human-like general intelligence. The Schema Network is a generative graphical model that can simulate the future, reason about cause and effect, and plan to reach distant rewards. In the ICML paper, we describe how Schema Networks can be learned directly from data and exhibit zero-shot generalization – for example, achieving high scores in the Breakout variations illustrated above after training only on the base game – precisely the setting where deep RL fails.
We used a game like Breakout in the paper to showcase the ability of Schema Networks to learn concepts that transfer from one variant to the next. Schema Networks also yield equally impressive results on other kinds of games. We would like to spotlight two more game styles we tested: Space Invaders and Sokoban. Space Invaders-like games involve many different mechanics from Breakout, including the frequent creation of objects (bullets) and the randomness inherent in enemy actions. Sokoban is vastly different from games like Breakout and Space Invaders because rewards are very rare, and scoring any points at all requires reasoning about object interactions across a much longer time horizon. The Sokoban planning problem is challenging for artificial and human intelligences alike.
Schema Networks rely on an input of entity states instead of raw images. Essentially, any trackable image feature could be an entity, which most typically includes objects, their boundaries, and their surfaces. In practice, we assume that a vision system is responsible for detecting and tracking entities from an image. Extracting entities from the Atari video games is not a hard computer vision problem, and recent work (Garnelo et al., 2016) has demonstrated one possible method for unsupervised entity construction using auto encoders.
Learning reusable concepts with Schema Networks
In Schema Networks, knowledge about the world is learned as small graphical model fragments called schemas. These schemas represent what they learn in terms of entities (think nouns), their attributes (adjectives), and interactions between entities (verbs) (c.f., Diuk et al., 2008). In new situations, appropriate knowledge fragments are instantiated automatically to make sense of the situation and guide the agent to success. Since the instantiated model can be represented as a probabilistic graphical model (PGM), the representation automatically deals with uncertain evidence and resolves multiple causes by explaining away. Moreover, planning can be treated as an inference problem and solved with efficient PGM inference algorithms (Attias, 2003).
The central substrate of the Schema Network is the schema. A schema describes how the future value of an entity’s attribute depends on the current values of that entity’s attributes and possibly other nearby entities. Each schema can be thought of as a predictor. These predictors are learned automatically from data. For instance, a schema might dictate that the Breakout ball’s velocity will change in the next frame, based on its current velocity and the relative position of a brick. Another schema might predict that the paddle will move to the left when the “left” action is taken by the player and there is an empty space to the left. Schemas may also predict rewards, entity creation, and entity deletion. The schema representation allows for automated forward and backward causal reasoning.
A Schema Network is completely characterized by a set of schemas. As a result, the model is highly interpretable. It is possible to examine each schema and immediately understand its implications. Since the Schema Network is a factor graph, different probabilistic inference algorithms can be used to predict future states and rewards conditioned on a current state. The same algorithm can be used to reason backwards from a target state because the model is generative. We demonstrate in our ICML paper how Max-Product Belief Propagation (MPBP) can be used to efficiently find reachable rewards in Breakout. The same MPBP-based planning mechanism is used for Sokoban, described below. Forward inference is sufficient to play Space Invaders well, and we demonstrate it using Monte Carlo Tree Search.
Learning in Schema Networks is an instance of structure learning in graphical models. We use a greedy algorithm based on linear and binary programming (see the ICML paper for details).
Breakout Results
We report in our ICML paper that Schema Networks are able to learn and generalize well from the standard version of Breakout to the variations illustrated above. Their performance on the variations is visualized in the GIFs below.
By learning a conceptual representation of a game, a Schema Network can reason its way to rewards. Below is a visualization showing how the Schema Network reasons about many potential futures by using its causal model of the world:

Space Invaders
Breakout and Space Invaders share some dynamics, such as the movement of the player and the relatively constant momentum of other game objects. However, Space Invaders diverges from Breakout in a number of interesting ways, e.g., a new “fire” action causes a bullet entity to be created just above the player ship. The differences between the games pose no theoretical barriers to Schema Networks, but present a few relatively minor engineering challenges: we introduced entity “creation” and “deletion” schemas into our learning pipeline. In addition, we optimized learning by ensuring we could reliably filter out noisy and unpredictable phenomena.
We also noticed that rewards in Space Invaders are more easily accessible than in Breakout, in the sense that random actions will quickly come upon both positive and negative rewards. We saw this as an opportunity to experiment with a simpler and faster planning method – Monte Carlo Tree Search (MCTS) – which requires only forward inference.
As we did for Breakout, we implemented our own version of Space Invaders to allow us to easily make small changes to the dynamics of the game, such as adjusting bullet speeds or changing bunker height, for the purpose of testing zero-shot transfer. Below is our reimplementation of Space Invaders, with a trained Schema Network controlling the player via MCTS.

A Schema Network trained on Space Invaders, playing the same game.
Over 30 trials, Schema Networks achieve Space Invaders scores of 46.5 (?=6.0), out of a maximum possible 50 points; roughly speaking, a score of 46.5 means that the algorithm plays perfectly a little over half of the time. For reference, a random policy scores -9.8 (?=11.6).
Is the Schema Network truly aiming to shoot the aliens and avoiding their bullets, or is it merely getting lucky? Below are two minor variations of the environment that better illustrate the agent’s “intentionality”. Observe, for instance, how the player on the right seems to avoid the initial barrage of bullets, take shelter under the bunker, and then fire towards the aliens when it has an opportunity. Its model of the world is not perfect – not all of its bullets strike an alien – but its predictions are more than sufficient to play the game variations well.

A Schema Network trained on Space Invaders, playing the same game.
We can also visualize the planning process to see what the agent is “thinking about” between each action. Since we use MCTS rather than the MPBP-based planning algorithm, probing the model and visualizing the planning below looks different. The MPBP algorithm first finds reachable rewards and then reasons backwards from a specific target. In contrast, MCTS explores possible future states by judiciously selecting hypothetical actions and accumulating the rewards that are found. As MCTS explores multiple possible futures, we shade objects according to the probability that they will be in their visualized position.

A Schema Network playing Space Invaders (in color) interleaved with its simulations of the game (in white).
The relatively small engineering effort required to get from Breakout to Space Invaders left us encouraged that Schema Networks could be adapted to a host of Atari-like games of different domains.
Original GameSingle AlienDouble AlienBunkers 3% HigherA3C44.2 (?=11.60)6.94 (?=6.52)6.06 (?=9.68)34.5 (?=17.64)Schema Nets46.5 (?=5.98)9.7 (?=4.21)10.7 (?=3.35)45.4 (?=8.78)Random-8.65 (?=12.21)7.45 (?=6.49)0.58 (?=13.17)-9.19 (?=12.77)
Sokoban is a puzzle game that involves pushing blocks to goal locations. An instance of Sokoban is pictured below. It is particularly challenging because it requires the player to plan multiple steps ahead while keeping the object interactions in mind. Sokoban solvers use domain specific information and can solve games up to a certain level of complexity. The goal of our work on Sokoban is not to compete with the dedicated solvers, but to show that Schema Networks can learn the game dynamics and plan actions in varied environments.

The goal of Sokoban is to push the blocks onto the targets. Sokoban problems range from the relatively trivial example shown here to complex problems that humans find extremely challenging.
New Sokoban puzzles can be created by changing the size and layout of the environment. Deep RL strategies that rely on the details of a specific layout cannot generalize to new puzzles that haven’t previously been seen. The only way an algorithm can solve novel Sokoban problems is by truly modeling the game dynamics in a way that supports forward and backward reasoning.
We investigated whether Schema Networks, trained in a small, simple version of Sokoban, can generalize to larger, more sophisticated instances of the game. The training environments are pictured below. They contain the same entities, interactions, and rewards as the full game, but facilitate faster training.

The Sokoban training data given to the Schema Network.
A Schema Network trained in this environment can readily generalize to a larger one, as shown below.

A Schema Network solving an instance of Sokoban larger and more complex than those in its training data.
How far can we push the planning capabilities of the trained Schema Network? We designed an instance of Sokoban that even a human player would find challenging. As shown below, the Schema Network is still able to find a solution.
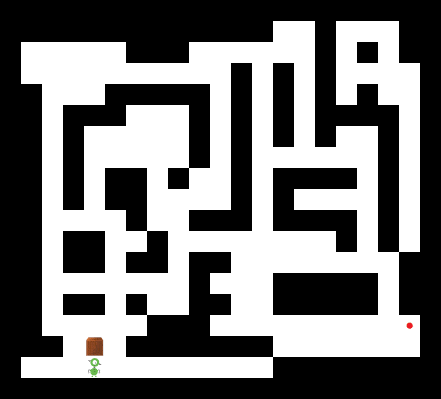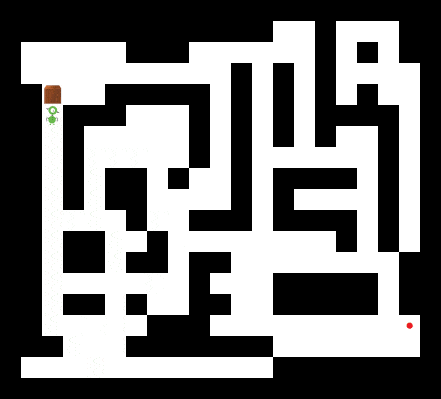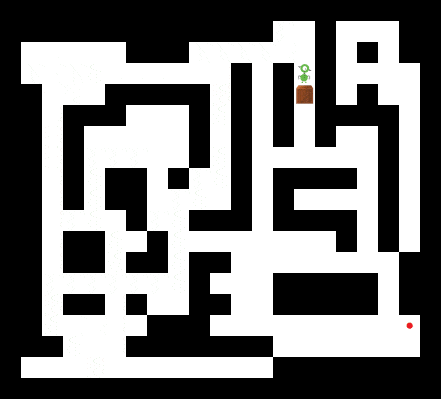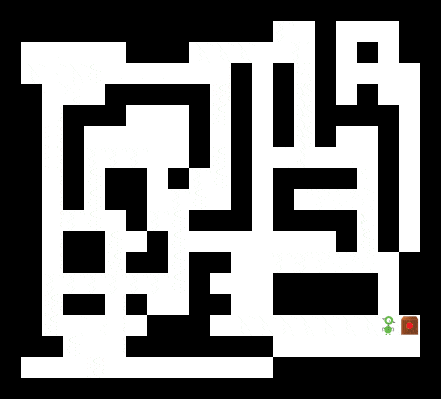
A Schema Network solving a much more challenging instance of Sokoban.
Discussion
End-to-end training and the ability to learn from raw pixels are often considered as advantages of deep RL. However, these advantages are interesting only when they lead to representations that generalize. Notably, even when the entity states are extracted and given as input to A3C, it leads only to a minor improvement in its generalization ability. End-to-end training in deep RL has the advantage of giving superior performance on a narrow task, while sacrificing generality.
What is the nature of the internal representations that leads to human-like generalization and transfer of prior experience (Lake et al., 2016)? We believe our work on Schema Networks sheds light on parts of this question. The modularity and compositionality of Schema Networks allow for wider flexibility and can accommodate changes in tasks without having to relearn the representations. Although beyond the scope of the current work, several aspects of Schema Network representation anticipate working interactively with a compositional generative model for vision which could lead to end-to-end systems with greater task generality.
Schema Networks are only one small step in this direction – much work remains. As described earlier, the current work relies on extracting entity states from raw images. Demonstrating Schema Networks working interactively with a generative vision system is an area that we are actively researching. Dealing with a wider range of variations and stochastic actions could require improvements in representation, inference and learning algorithms. Stochasticity in Arcade Learning Environments (Bellemare et al., 2015) were introduced to counter the effect of agents that rely on brute force memorization. Since Schema Networks do not rely on brute force memorization (as demonstrated through our experiments on generalization), this aspect of stochasticity is not relevant for our tests, and we focused on emulating the non-stochastic Atari 2600 environments that are easier to learn using our current learning algorithms. Efficiently learning schemas in the presence of stochastic actions is also an area of active research for us.
Games like Breakout, Space Invaders, and Sokoban can be helpful environments for developing new AI algorithms. At their best, games can provide researchers with quick signal on whether an approach holds promise for more realistic applications. However, isolated results on games should be interpreted with caution. For AI research, more important than a method’s final score on a particular game is the method’s potential to acquire conceptual knowledge which enables it to generalize beyond the training game.
State-of-the-art deep reinforcement learning models may surpass human-level scores from the environments on which they are trained, but they do not learn reusable human-like concepts. Changes to their environments that seem minor to humans leave the trained models confused and unable to recover. In contrast, Schema Networks are able to learn the dynamics of their training environment in such a way that permits instant generalization to many variations. In this way, Schema Networks learn causes, effects, and concepts. We hope that our work will encourage others to consider models with similarly rich structure, and to view zero-shot generalization as one of the most important requirements for any AI system.
Join Us
We hope that our work will encourage others to consider models with similarly rich structure, and to view zero-shot generalization as one of the most important requirements for any AI system. If these ideas resonated with you, please check out our open positions or more information about Vicarious at our home page.
References
Attias, Hagai. Planning by probabilistic inference. In AISTATS, 2003.
Battaglia, Peter, Pascanu, Razvan, Lai, Matthew, Rezende, Danilo Jimenez, et al. Interaction networks for learning about objects, relations and physics. In Advances in Neural Information Processing Systems, pp. 4502–4510, 2016.
Bellemare, Marc, Yavar Naddaf, Joel Veness, and Michael Bowling. "The arcade learning environment: An evaluation platform for general agents." In Twenty-Fourth International Joint Conference on Artificial Intelligence. 2015.
Chang, Michael B, Ullman, Tomer, Torralba, Antonio, and Tenenbaum, Joshua B. A compositional object-based approach to learning physical dynamics. arXiv preprint arXiv:1612.00341, 2016.
Diuk, Carlos, Cohen, Andre, and Littman, Michael L. An object-oriented representation for efficient reinforcement learning. In Proceedings of the 25th International Conference on Machine Learning, pp. 240–247. ACM, 2008.
Drescher, Gary L. Made-up minds: a constructivist approach to artificial intelligence. MIT press, 1991.
Garnelo, Marta, Arulkumaran, Kai, and Shanahan, Murray. Towards deep symbolic reinforcement learning. arXiv preprint arXiv:1609.05518, 2016.
Jordan, Michael Irwin. Learning in graphical models, volume 89. Springer Science & Business Media, 1998.
Koller, Daphne and Friedman, Nir. Probabilistic graphical models: principles and techniques. MIT press, 2009.
Lake, Brenden M., Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. "Building machines that learn and think like people." arXiv preprint arXiv:1604.00289 (2016).
Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Rusu, Andrei A, Veness, Joel, Bellemare, Marc G, Graves, Alex, Riedmiller, Martin, Fidjeland, Andreas K, Ostrovski, Georg, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529– 533, 2015.
Mnih, Volodymyr, Badia, Adria Puigdomenech, Mirza, Mehdi, Graves, Alex, Lillicrap, Timothy, Harley, Tim, Silver, David, and Kavukcuoglu, Koray. Asynchronous methods for deep reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, pp. 1928–1937, 2016.
Rusu, Andrei A, Rabinowitz, Neil C, Desjardins, Guillaume, Soyer, Hubert, Kirkpatrick, James, Kavukcuoglu, Koray, Pascanu, Razvan, and Hadsell, Raia. Progresive neural networks. arXiv preprint arXiv:1606.04671, 2016.
Silver, David, Huang, Aja, Maddison, Chris J, Guez, Arthur, Sifre, Laurent, Van Den Driessche, George, Schrittwieser, Julian, Antonoglou, Ioannis, Panneershelvam, Veda, Lanctot, Marc, et al. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016a.
Silver, David, van Hasselt, Hado, Hessel, Matteo, Schaul, Tom, Guez, Arthur, Harley, Tim, Dulac-Arnold, Gabriel, Reichert, David, Rabinowitz, Neil, Barreto, Andre, et al. The predictron: End-to-end learning and planning. arXiv preprint arXiv:1612.08810, 2016b.
Tamar, Aviv, Levine, Sergey, Abbeel, Pieter, WU, YI, and Thomas, Garrett. Value iteration networks. In Advances in Neural Information Processing Systems, pp. 2146– 2154, 2016.
Taylor, Matthew E and Stone, Peter. Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research, 10(Jul):1633–1685, 2009.
Van Hasselt, Hado, Guez, Arthur, and Silver, David. Deep reinforcement learning with double q-learning. In AAAI, pp. 2094–2100, 2016.
Watter, Manuel, Springenberg, Jost, Boedecker, Joschka, and Riedmiller, Martin. Embed to control: A locally linear latent dynamics model for control from raw images. In Advances in Neural Information Processing Systems, pp. 2746–2754, 2015.